Workplace monitoring
by Anonymous on September 30, 2018
We never intended to build a pervasive workplace monitoring system – We just wanted to replace a clunky system of shared spreadsheets and email.
Our new system was intended to track customer orders as they moved through the factory. Workers finding a problem in the production process could quickly check order history and take corrective action. As a bonus, the system would also record newly-mandatory safety-related records. And it also appealed to the notion of “Democratization of Data,” giving workers direct access to customer orders. No more emails or phone-tag with production planners.
It goes live
The system was well received, and we started collecting a lot of data: a log every action performed on each sales order, with user IDs and timestamps. Workers could see all the log entries for each order they processed. And the log entries became invisible to workers once an order was closed.
Invisible, but
not deleted.

Two years later, during a time of cost-cutting, it came to the attention of management that the logs could be consolidated and sorted by *any* field. Like this:
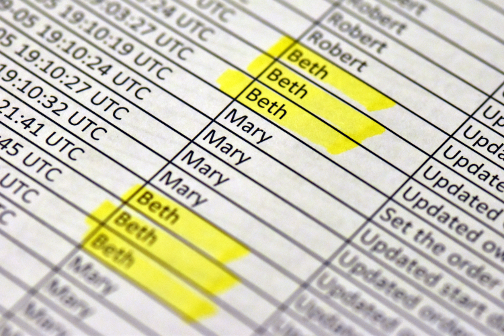
A new report was soon generated; logs sorted by worker ID. It didn’t
seem like such a major request. After all, the data was already there. No notice was given to workers about the new report, or its potential use as a worker performance evaluation tool.
 Re-purposed data
Re-purposed data
The personally identifiable information was re-purposed without notice or consent. The privacy issue may be intangible now to the workers, but could one day become very tangible as a factor in pay or layoff decisions. There is also potential for misinterpretation of the data. A worker doing many small tasks could be seen as doing far more than a worker doing a few time-consuming tasks.
 Protection for workers’ information
Protection for workers’ information
California employers may
monitor workers’ computer usage. The California Consumer Privacy act of 2018 covers consumers, not workers.
However, European Union’s General Data Protection Regulation
(GDPR) addresses this directly, and some related portions of the system operate in the EU.
GDPR’s scope is broad; covering personally identifiable information in all walks of life (e.g. as a worker, as consumer, as citizen.) Section 26 makes clear: “The principles of data protection should apply to any information concerning an identified or identifiable natural person.” Other sections cover consent, re-purposing, and fairness/transparency issues, and erasability (sections 32, 60, 65, and 66.)
Most particularly, Article 88 requires that collection and use of personally identifiable information in workplace should be subject to particularly high standards of transparency.
Failings
It’s easy in hindsight to find multiple points at which this might have been avoided.
Mulligan’s and
Solove’s frameworks suggest looking at “actors” and causes.
- Software Developer’s action (harm during data collection): There could have been a login at the level of a processing station ID, rather than a worker’s personal ID.
- Software Developer’s action (and timescale considerations, yielding harm during data processing): The developer could have completely deleted the worker IDs once the order closed.
- Software Developer’s action (harm during data processing and dissemination: increased Accessibility, Distortion): The
developer could have written the report to show that simple “event counting” wasn’t a reliable way of measuring worker contribution.
- Management’s action (harm during data gathering and processing): the secondary use of the data resulted in intrusive surveillance. Businesses have responsibility (particularly under GDPR) to be transparent with respect to workplace data. Due concern for the control over personal information was not shown.
Prevention
One way forward, when working on systems which evolve over time: Consider Mulligan’s
contrast concept dimension of privacy analysis, applied with Solove’s meta-harm categories. Over the full evolutionary life of a software system, we can ask: “What is private and what is not?” If the actors – developer, manager, and even workers – had asked, as each new feature was requested: “What is being newly exposed, and what is made private,” they might not have drifted into the current state. It’s a question which could readily be built into formal software development processes.
But in an era of “Data Democratization,” when data-mining may be more broadly available withing organizations, such checklists might be necessary but not sufficient. Organizations will likely need broadly-based internal training on protection of personal information.

 Two years later, during a time of cost-cutting, it came to the attention of management that the logs could be consolidated and sorted by *any* field. Like this:
Two years later, during a time of cost-cutting, it came to the attention of management that the logs could be consolidated and sorted by *any* field. Like this:
 A new report was soon generated; logs sorted by worker ID. It didn’t seem like such a major request. After all, the data was already there. No notice was given to workers about the new report, or its potential use as a worker performance evaluation tool.
A new report was soon generated; logs sorted by worker ID. It didn’t seem like such a major request. After all, the data was already there. No notice was given to workers about the new report, or its potential use as a worker performance evaluation tool.
 Re-purposed data
The personally identifiable information was re-purposed without notice or consent. The privacy issue may be intangible now to the workers, but could one day become very tangible as a factor in pay or layoff decisions. There is also potential for misinterpretation of the data. A worker doing many small tasks could be seen as doing far more than a worker doing a few time-consuming tasks.
Re-purposed data
The personally identifiable information was re-purposed without notice or consent. The privacy issue may be intangible now to the workers, but could one day become very tangible as a factor in pay or layoff decisions. There is also potential for misinterpretation of the data. A worker doing many small tasks could be seen as doing far more than a worker doing a few time-consuming tasks.
 Protection for workers’ information
California employers may monitor workers’ computer usage. The California Consumer Privacy act of 2018 covers consumers, not workers.
However, European Union’s General Data Protection Regulation (GDPR) addresses this directly, and some related portions of the system operate in the EU.
GDPR’s scope is broad; covering personally identifiable information in all walks of life (e.g. as a worker, as consumer, as citizen.) Section 26 makes clear: “The principles of data protection should apply to any information concerning an identified or identifiable natural person.” Other sections cover consent, re-purposing, and fairness/transparency issues, and erasability (sections 32, 60, 65, and 66.)
Most particularly, Article 88 requires that collection and use of personally identifiable information in workplace should be subject to particularly high standards of transparency.
Failings
It’s easy in hindsight to find multiple points at which this might have been avoided. Mulligan’s and Solove’s frameworks suggest looking at “actors” and causes.
Protection for workers’ information
California employers may monitor workers’ computer usage. The California Consumer Privacy act of 2018 covers consumers, not workers.
However, European Union’s General Data Protection Regulation (GDPR) addresses this directly, and some related portions of the system operate in the EU.
GDPR’s scope is broad; covering personally identifiable information in all walks of life (e.g. as a worker, as consumer, as citizen.) Section 26 makes clear: “The principles of data protection should apply to any information concerning an identified or identifiable natural person.” Other sections cover consent, re-purposing, and fairness/transparency issues, and erasability (sections 32, 60, 65, and 66.)
Most particularly, Article 88 requires that collection and use of personally identifiable information in workplace should be subject to particularly high standards of transparency.
Failings
It’s easy in hindsight to find multiple points at which this might have been avoided. Mulligan’s and Solove’s frameworks suggest looking at “actors” and causes.