Unknown Knowns
by Anonymous on 10/21/2018
 Image Credit: https://www.azquotes.com/quote/254214
Donald Rumsfeld during Department of Defense News Briefing, archive.defense.gov. February 12, 2002.
Image Credit: https://www.azquotes.com/quote/254214
Donald Rumsfeld during Department of Defense News Briefing, archive.defense.gov. February 12, 2002.
The taxonomy of knowledge laid out by Rumsfeld in his much quoted new briefing conspicuously omits a fourth category: unknown knowns. In his critique of Rumsfeld’s analysis, the philosopher Slavoj Žižek defines the unknown knowns as “the disavowed beliefs and suppositions we are not even aware of adhering to ourselves, but which nonetheless determine our acts and feelings.” While this may seem like the realm of psychoanalysis, it’s a term that could also be applied to two of the most important topics in machine learning today: bias and interpretability.
The battle against bias, especially illegal biases that discriminate against protected classes, is a strong focus for both academia and industry. Simply testing the outputs of an algorithm for different categories of people for statistical difference can reveal things about the decision making process that were previous unknown, flipping things from the “unknown known” state to “known known.” More advanced interpretability tools, like
LIME, are able to reveal even more subtle relationships between inputs and outputs.
While swaths of “unknown knowns” are being converted to “known knowns” with new techniques and attention, there’s still a huge amount of “unknown knowns” that we will miss forever. Explicitly called out protected classes are becoming easier to measure, but it’s rare to check for all possible intersections of protected classes. For example, there may be know measurable bias in some task when comparing genders or across race separately, but there may be bias when looking at the combinations. The fundamental nature of intersections is that their populations become smaller as more dimensions are considered, so the statistical tests become less powerful and it’s harder for automated tools to identify bias with certainty.
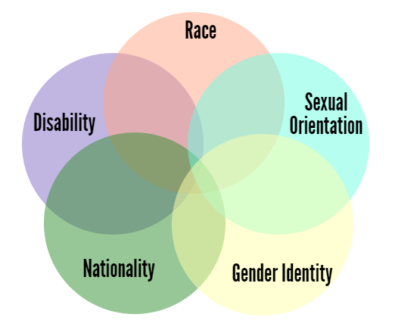 Image Credit: https://www.ywboston.org/2017/03/what-is-intersectionality-and-what-does-it-have-to-do-with-me/
Image Credit: https://www.ywboston.org/2017/03/what-is-intersectionality-and-what-does-it-have-to-do-with-me/
There are are also many sub-classes that we don’t even know to look for bias against and have to rely on chance to discover. For example, in
2014 Target was called out for predicting pregnancies based on shopping patterns. Their Marketing Analytics team had a hypothesis that they could target pregnant women and made the explicit choice to single out this population, but with modern unsupervised learning techniques it could have just as easily been an automatically deployed campaign where no human had ever seen the description of the target audience.
“Pregnant women” as a category is easy to describe and the concerns about such targeting are easy to stir up controversy and change corporate behaviour, but more niche groups that may be biased against by algorithms may never be noticed. It’s also troubling that there may be classes discovered by unsupervised learning algorithm that have no obvious description yet, but would be controversial if given a name.
So what can be done? It may seem like a contradiction to try and address unknown knowns, given that they’re unknown, but new interpretability tools are changing what can be known. Practitioners could also start dedicating more of their model validation time to exploring the full set of combinations of protected classes, rooting out the subtle biases that might be missed with separate analysis of each category. A less technical but more ambitious solution is for organizations and practitioners to start sharing the biases they’ve discovered in their models and to contribute to some sort of central repository that others can learn from.

 Image Credit: https://www.azquotes.com/quote/254214
Donald Rumsfeld during Department of Defense News Briefing, archive.defense.gov. February 12, 2002.
The taxonomy of knowledge laid out by Rumsfeld in his much quoted new briefing conspicuously omits a fourth category: unknown knowns. In his critique of Rumsfeld’s analysis, the philosopher Slavoj Žižek defines the unknown knowns as “the disavowed beliefs and suppositions we are not even aware of adhering to ourselves, but which nonetheless determine our acts and feelings.” While this may seem like the realm of psychoanalysis, it’s a term that could also be applied to two of the most important topics in machine learning today: bias and interpretability.
The battle against bias, especially illegal biases that discriminate against protected classes, is a strong focus for both academia and industry. Simply testing the outputs of an algorithm for different categories of people for statistical difference can reveal things about the decision making process that were previous unknown, flipping things from the “unknown known” state to “known known.” More advanced interpretability tools, like LIME, are able to reveal even more subtle relationships between inputs and outputs.
While swaths of “unknown knowns” are being converted to “known knowns” with new techniques and attention, there’s still a huge amount of “unknown knowns” that we will miss forever. Explicitly called out protected classes are becoming easier to measure, but it’s rare to check for all possible intersections of protected classes. For example, there may be know measurable bias in some task when comparing genders or across race separately, but there may be bias when looking at the combinations. The fundamental nature of intersections is that their populations become smaller as more dimensions are considered, so the statistical tests become less powerful and it’s harder for automated tools to identify bias with certainty.
Image Credit: https://www.azquotes.com/quote/254214
Donald Rumsfeld during Department of Defense News Briefing, archive.defense.gov. February 12, 2002.
The taxonomy of knowledge laid out by Rumsfeld in his much quoted new briefing conspicuously omits a fourth category: unknown knowns. In his critique of Rumsfeld’s analysis, the philosopher Slavoj Žižek defines the unknown knowns as “the disavowed beliefs and suppositions we are not even aware of adhering to ourselves, but which nonetheless determine our acts and feelings.” While this may seem like the realm of psychoanalysis, it’s a term that could also be applied to two of the most important topics in machine learning today: bias and interpretability.
The battle against bias, especially illegal biases that discriminate against protected classes, is a strong focus for both academia and industry. Simply testing the outputs of an algorithm for different categories of people for statistical difference can reveal things about the decision making process that were previous unknown, flipping things from the “unknown known” state to “known known.” More advanced interpretability tools, like LIME, are able to reveal even more subtle relationships between inputs and outputs.
While swaths of “unknown knowns” are being converted to “known knowns” with new techniques and attention, there’s still a huge amount of “unknown knowns” that we will miss forever. Explicitly called out protected classes are becoming easier to measure, but it’s rare to check for all possible intersections of protected classes. For example, there may be know measurable bias in some task when comparing genders or across race separately, but there may be bias when looking at the combinations. The fundamental nature of intersections is that their populations become smaller as more dimensions are considered, so the statistical tests become less powerful and it’s harder for automated tools to identify bias with certainty.
 Image Credit: https://www.ywboston.org/2017/03/what-is-intersectionality-and-what-does-it-have-to-do-with-me/
There are are also many sub-classes that we don’t even know to look for bias against and have to rely on chance to discover. For example, in 2014 Target was called out for predicting pregnancies based on shopping patterns. Their Marketing Analytics team had a hypothesis that they could target pregnant women and made the explicit choice to single out this population, but with modern unsupervised learning techniques it could have just as easily been an automatically deployed campaign where no human had ever seen the description of the target audience.
“Pregnant women” as a category is easy to describe and the concerns about such targeting are easy to stir up controversy and change corporate behaviour, but more niche groups that may be biased against by algorithms may never be noticed. It’s also troubling that there may be classes discovered by unsupervised learning algorithm that have no obvious description yet, but would be controversial if given a name.
So what can be done? It may seem like a contradiction to try and address unknown knowns, given that they’re unknown, but new interpretability tools are changing what can be known. Practitioners could also start dedicating more of their model validation time to exploring the full set of combinations of protected classes, rooting out the subtle biases that might be missed with separate analysis of each category. A less technical but more ambitious solution is for organizations and practitioners to start sharing the biases they’ve discovered in their models and to contribute to some sort of central repository that others can learn from.
Image Credit: https://www.ywboston.org/2017/03/what-is-intersectionality-and-what-does-it-have-to-do-with-me/
There are are also many sub-classes that we don’t even know to look for bias against and have to rely on chance to discover. For example, in 2014 Target was called out for predicting pregnancies based on shopping patterns. Their Marketing Analytics team had a hypothesis that they could target pregnant women and made the explicit choice to single out this population, but with modern unsupervised learning techniques it could have just as easily been an automatically deployed campaign where no human had ever seen the description of the target audience.
“Pregnant women” as a category is easy to describe and the concerns about such targeting are easy to stir up controversy and change corporate behaviour, but more niche groups that may be biased against by algorithms may never be noticed. It’s also troubling that there may be classes discovered by unsupervised learning algorithm that have no obvious description yet, but would be controversial if given a name.
So what can be done? It may seem like a contradiction to try and address unknown knowns, given that they’re unknown, but new interpretability tools are changing what can be known. Practitioners could also start dedicating more of their model validation time to exploring the full set of combinations of protected classes, rooting out the subtle biases that might be missed with separate analysis of each category. A less technical but more ambitious solution is for organizations and practitioners to start sharing the biases they’ve discovered in their models and to contribute to some sort of central repository that others can learn from.