Dataset: Wiki Neutrality Corpus

The primary dataset is the Wiki Neutrality Corpus (WNC), a collection of sentence changes made under Wikipedia’s neutral point of view policy, containing over 180,000 pairs of sentences. The dataset can be found at this Kaggle page, and the paper that introduced the dataset can be found here. Although the data was relatively clean, exploratory data analysis revealed numerous duplicates which were subsequently removed. Additionally, cosine similarity was employed to identify and exclude records deemed too similar. Above is a set of examples from the WNC. The dataset includes examples of framing bias as well as demographic biases, such as gendered and religious language. For the classification task, the Source and Target sentences were labeled as biased and neutral, respectively. For the neutralization task, the Source/Target pairs were retained together.
Overview of Models
As an overview, BIASCheck is comprised of two models: a bias detection task and a bias neutralization task. The bias detection task is a classification model used to determine if inputted text is “biased” or “neutral”, labeling text biased if the score is greater than or equal to 50%. If the text is biased, the text is neutralized in an LLM-based bias neutralization task. To qualify if the LLM did an adequate job, the output from the LLM is passed back through the classification task to test for bias. Below is an overview of our evaluation process flow:
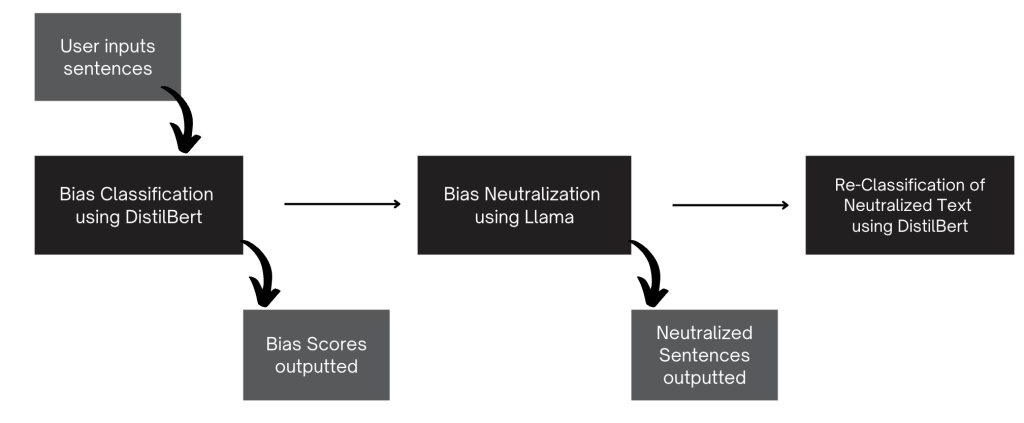
Evaluation
- For each inputted sentence, the MVP automatically detects subjective bias and provide bias percentage scores.
- For biased sentences, the tool then provides actionable insights on biases by suggesting neutral alternatives.
- For internal testing, we reclassify neutralized text.
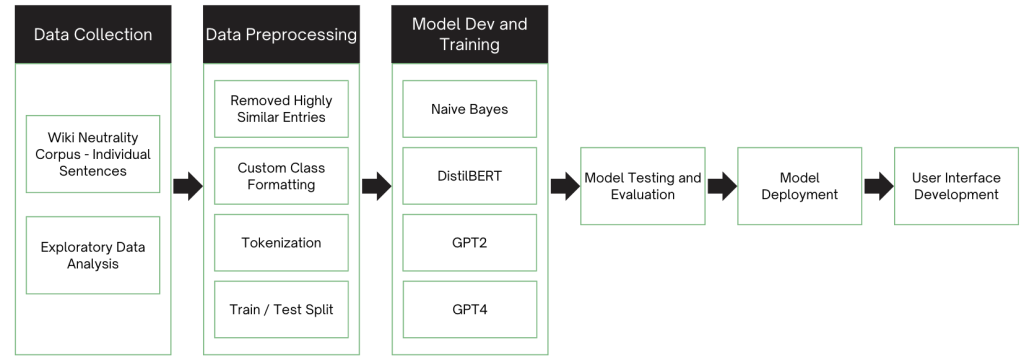
Bias Detection Process Flow
- We cleaned our data, removing highly similar text entries, and formatted our classes for modeling purposes.
- Naive Bayes and GPT2 models (not the generative version) were used as baseline for binary classification or detection of bias.
- Transformer models, including the light-weight DistilBERT, were used to augment performance.
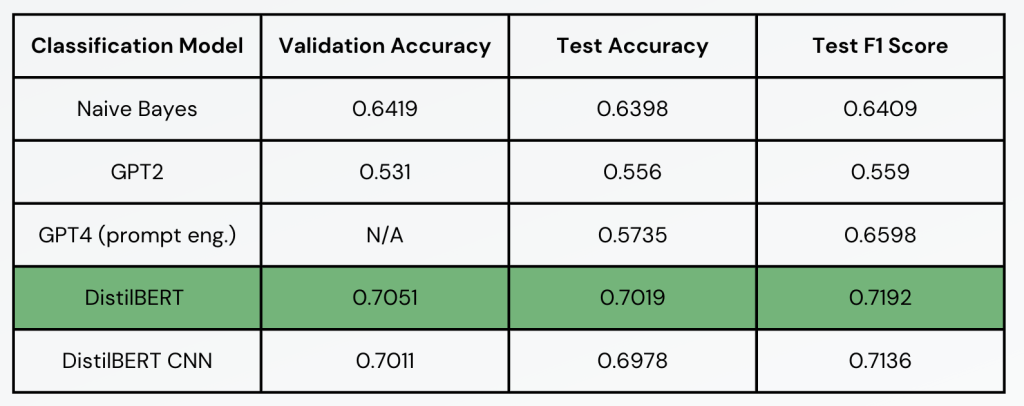
Bias Detection Results
- All models except GPT4 were fine tuned using Wiki Neutrality Corpus.
- Parameter grid search was conducted using a small sample of the dataset.
- Our best classification model is a DistilBERT model using 512 max sequence length, CLS token, 1 hidden layer, sigmoid classification, Adam optimizer, fine-tuned for 3 epochs
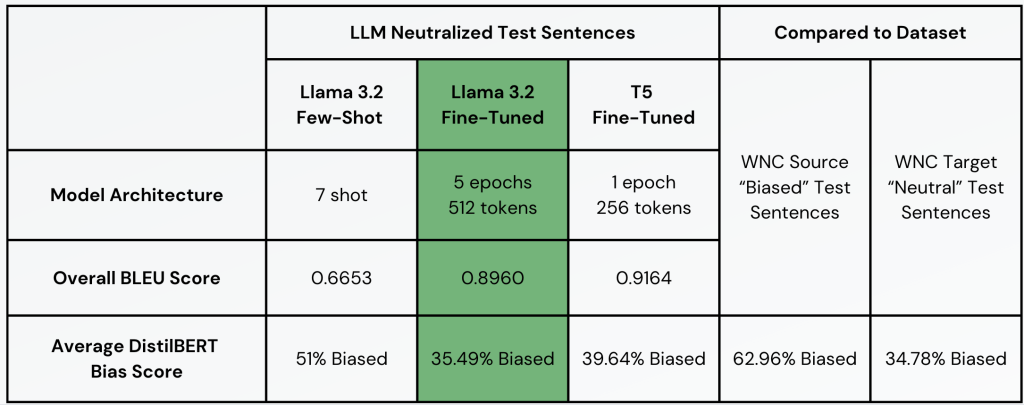
Bias Neutralization Results & Testing
- Bias Neutralization Results & Testing
- The process flow for this task was similar to bias detection through preprocessing. We developed three models:
- llama 3.2 prompt engineered
- llama 3.2 fine tuned
- T5 fine tuned model
- To evaluate the neutralization models, the test dataset was processed through each model, and the outputs were compared to the target neutral sentences in the Wiki Neutrality dataset. Evaluation metrics included overall BLEU scores and average DistilBERT bias scores, calculated by passing the neutralized sentences through the DistilBERT classifier. Additionally, the average DistilBERT scores of the dataset’s source and target sentences were measured as a baseline. The fine-tuned LLaMA model achieved the best performance, with an overall BLEU score of 0.896 and an average bias score of 35.49%, closely aligning with the target baseline of 34.78%.

Bias Neutralization Testing
We conducted additional analysis of our best neutralization model by examining our neutralized outputs and comparing them to our target sentences. We see that even though our model doesn’t always exactly match the target sentence, it still neutralizes the bias. for example, with the second entry our model matches the target exactly. In the third example, the target changes holy union to personal union, and our model just drops holy to say marriage is a union.